
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 쿠키
- 프로그래머스
- 디버깅
- docker
- JPA
- 결제서비스
- 아키텍쳐 개선
- 몽고 인덱스
- spring event
- 검색어 추천
- 추천 검색 기능
- 백준
- 레디스 동시성
- 크롤링
- 구현
- 누적합
- gRPC
- next-stock
- jwt 표준
- 카카오
- 트랜잭샨
- ai agent
- piplining
- ipo 매매자동화
- 셀러리
- AWS
- BFS
- 완전탐색
- langgraph
- 이분탐색
- Today
- Total
코딩관계론
TPS 2에서 TPS 10,000까지의 험난한 과정 본문
🔥 성능 개선 목표 설정
서비스 이벤트가 열리면 100,000명의 사용자가 초당 5회의 요청을 수행하게 됩니다. 이 서비스는 10분간 유지되므로 초당 QPS는 8,400 TPS를 감당해야 합니다. (QPS와 TPS를 동일로 가정)
🚩 초기 문제 발견
DDD 기반으로 타임딜 서비스를 리팩토링한 뒤 성능 테스트를 진행했으나, TPS가 2라는 극단적으로 낮은 결과가 나왔습니다.

프로메테우스를 통해 분석한 결과, DB 커넥션 풀이 10개뿐이라 요청이 몰릴 경우 모든 커넥션이 활성화되고 대기 요청이 쌓이는 현상이 발생했습니다.
하지만 Look Aside 캐싱 패턴을 사용했기 때문에, 최초 요청만 DB에 접근하고 이후 요청은 Redis에서 처리해야 했습니다. 원인을 분석한 결과, 캐시 접근 이전에 트랜잭션이 시작되면서 불필요한 DB 커넥션을 차지했습니다.

⚙️ 문제 해결 및 1차 개선
트랜잭션의 위치를 캐시 확인 이후로 변경했습니다. 결과적으로 첫 요청만 DB 커넥션이 활성화되고, 이후 요청은 DB 커넥션을 사용하지 않게 되어 TPS가 100으로 증가했습니다.

🔎 추가 병목 구간 분석
추가적으로 목표 TPS(8,400)에 미치지 못한 이유는 분산 락(Distributed Lock) 사용으로 인한 병목이었습니다. 쿠폰 발급 정합성을 유지하기 위해 사용한 분산 락은 요청이 많아질수록 성능 저하를 일으켰습니다.
🚀 큐(Queue)를 통한 성능 개선 시도
분산 락 대신, 정합성과 요청 순서를 동시에 보장할 수 있는 큐(Queue)를 도입했습니다. 요청을 큐에 담아 순서대로 처리하여, 정합성을 보장하고 TPS를 높이고자 했습니다.

그러나 TPS가 2,400에서 정체됐고, 이후 요청들이 실패하는 현상이 발생했습니다.

📉 GC 분석 및 네트워크 병목 확인
성능 저하의 원인으로 GC를 의심했으나 GC는 성능에 미치는 영향이 크지 않았습니다. 추가 분석 결과, 네트워크 병목으로 인해 요청 실패가 발생한 것을 확인했습니다. 부하 테스트 서버를 클라우드 환경으로 이동하여 네트워크 병목 문제를 해소했습니다.
이후 TPS는 2,000에서 안정화되었지만, 목표(8,400 TPS)에 미치지 못했습니다.
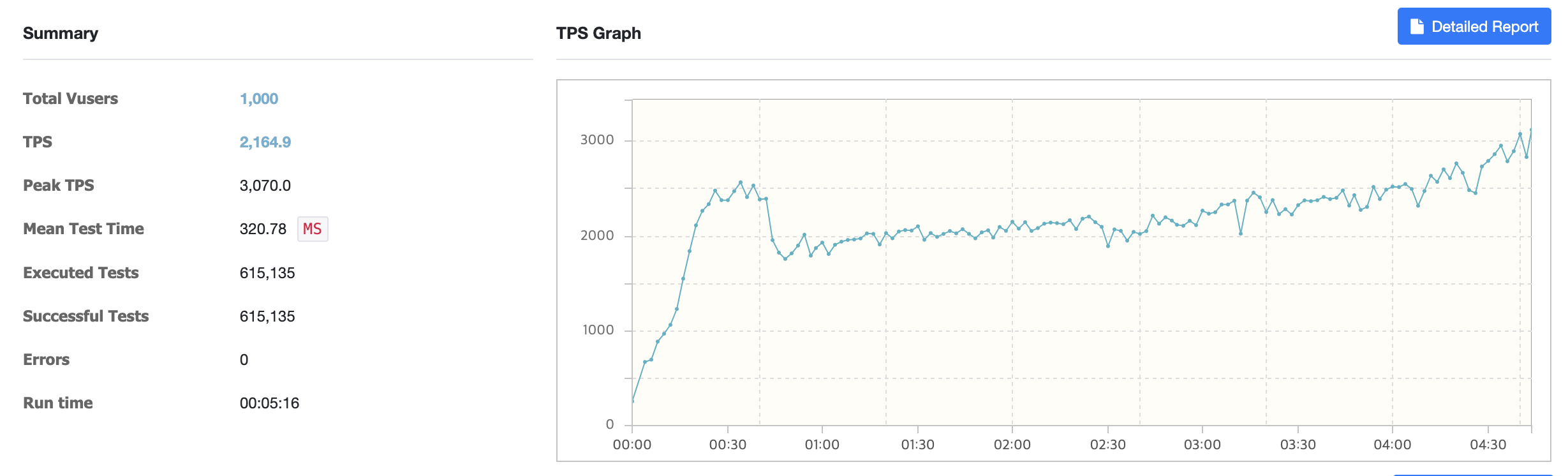
🛠️ Scale-Out 도입 및 문제점 발견
성능 개선을 위해 Scale-Out을 적용했으나 두 가지 문제가 발생했습니다.
- 예상한 TPS 증가 효과가 나타나지 않았습니다.
- 발급 가능한 쿠폰 수를 초과하는 쿠폰이 발급됐습니다.

원인은 비용 절감을 위해 Nginx와 Infra 서버를 함께 사용하면서 네트워크와 CPU 병목 현상이 발생했기 때문입니다.
🧩 병목 구간 재구조화
네트워크 및 CPU 병목 해소를 위해 Redis에서 TTL로 관리하던 구조를 제거하고 DB에 직접 저장하는 구조로 변경했습니다. 또한 단일 병목 지점 해소를 위해 Infra 서버를 Scale-Up하여 성능을 개선했습니다.
결과적으로 TPS가 7,000으로 증가했습니다.

🔑 정합성 문제 해결 및 분산 락 활용
Worker 서버가 늘어나면서 발생하는 정합성 문제는 다시 분산 락을 도입하여 해결했습니다. 쿠폰 발급 개수만 Event 테이블에서 관리하고, 이 데이터의 정합성만 락으로 보호하여 성능 저하를 최소화했습니다.
최종적으로, Worker 서버를 추가로 생성한 후 테스트한 결과 평균 9,000 TPS, 최대 10,000 TPS를 달성했습니다.

🐝 꿀팁: Redis의 ScoredSortedSet 활용
Redis의 ScoredSortedSet을 우선순위 큐로 사용하면 중복 참여가 자동으로 방지되며, 삽입/삭제/검색 연산 성능이 O(Log(N))으로 매우 효율적입니다.
'개발' 카테고리의 다른 글
| 결제서비스 (0) | 2024.09.02 |
|---|---|
| Redis 분산 시스템에서의 동시성 문제 해결 (0) | 2024.08.25 |
| Redis 객체가 소멸될 때 DB에 영속화하자 - 꿀팁있음 (0) | 2024.08.19 |
| 검색어 추천 서비스 V4(Sharding) (0) | 2024.08.13 |
| CAP 이론 - Consistency (일관성), Availability (가용성), Partition Tolerance (파티션 감내) (0) | 2024.08.13 |



