
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 카카오
- gRPC
- 누적합
- AWS
- docker
- 수신자 대상 다르게
- 좋은 코드 나쁜 코드
- 완전탐색
- 숫자 블록
- 코드 계약
- 결제서비스
- jwt 표준
- 이분탐색
- 백준
- 객체지향패러다임
- 프로그래머스
- 레디스 동시성
- 트랜잭샨
- piplining
- branch 전략
- 알람 시스템
- 디버깅
- prg 패턴
- 구현
- 검색어 추천
- 쿠키
- 깊게 생각해보기
- 셀러리
- spring event
- BFS
- Today
- Total
코딩관계론
In-memory- database를 사용해 TPS를 높이자 본문
서론
기존의 타임딜 서비스를 구현하고 나서, nGrinder를 이용해 부하테스트를 진행했습니다. 900명의 유저가 동시에 접근해서 쿠폰 지급을 요청할 때, TPS가 190, 평균 응답시간은 2.3초가 나왔습니다.
따라서 부하가 많이 나오는 지점을 파악하여 성능을 개선 할 필요가 생겼습니다. 병목지점은 DB의 비관적 락부분과 실제 HDD까지 쓰기 작업이 완료되고 나서야 사용자에게 응답을 보내는 구조가 문제라고 생각했습니다.
따라서 이러한 문제점을 해결하기 위해 위해 In memory database를 도입하게 됐고, 궁극적으로 성능이 어떻게 개선됐는지 말씀드리겠습니다.
In-memory-db를 도입했는가?
속도적 측면
아래 그림을 보면 속도적 측면이 있다. Redis에 접근해서 데이터를 읽을 때는 100ns + 네트워크 지연만 있으면 되지만, 데이터베이스의 경우에는 1ms + 네트워크 지연만 있으면 된다.

인프라 측면
데이터베이스(DB)의 부하가 심해져서 스케일 아웃(Scale-Out)을 한다고 가정해보자. 그렇게 된다면 기존의 인프라 방식에서는 데이터(발급 가능한 쿠폰의 개수)를 어디에 저장해야 할지 규칙을 정해야만 한다. 하지만 미들웨어로 레디스 서버를 도입하게 되면 레디스에 쿠폰의 개수를 저장하는 캐시 서버를 둠으로써 데이터의 정합성을 보장할 수 있을 것이다.

성능 개선
기존의 구조는 사용자의 요청이 도달하면 데이터베이스의 물리적 락을 획득해 경쟁조건을 제거하는 방식이었다. 즉 사용자가 많아지면 Lock 대기시간이 길어져서 TPS 성능이 안나오게 되고, 응답 대기시간이 길어질 것이다.
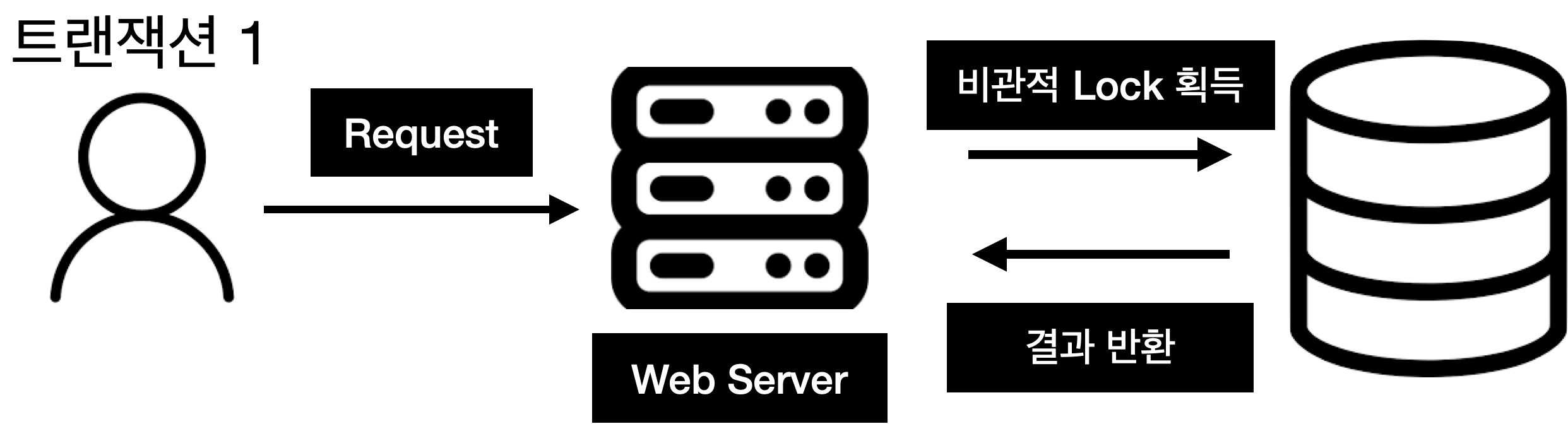
하지만 다음과 같은 구조를 사용했을 때는 사용자의 요청에 딜레이가 거의 없을 것이다. 기존에는 디스크의 Lock을 잡는 과정이라면 이제는 메모리의 락을 잡는 과정에 있기 때문에 락 요청 시간이 절감되고, 사용자의 요청은 데이터베이스에 Read/Write과는 상관없이 처리되기 때문이다.
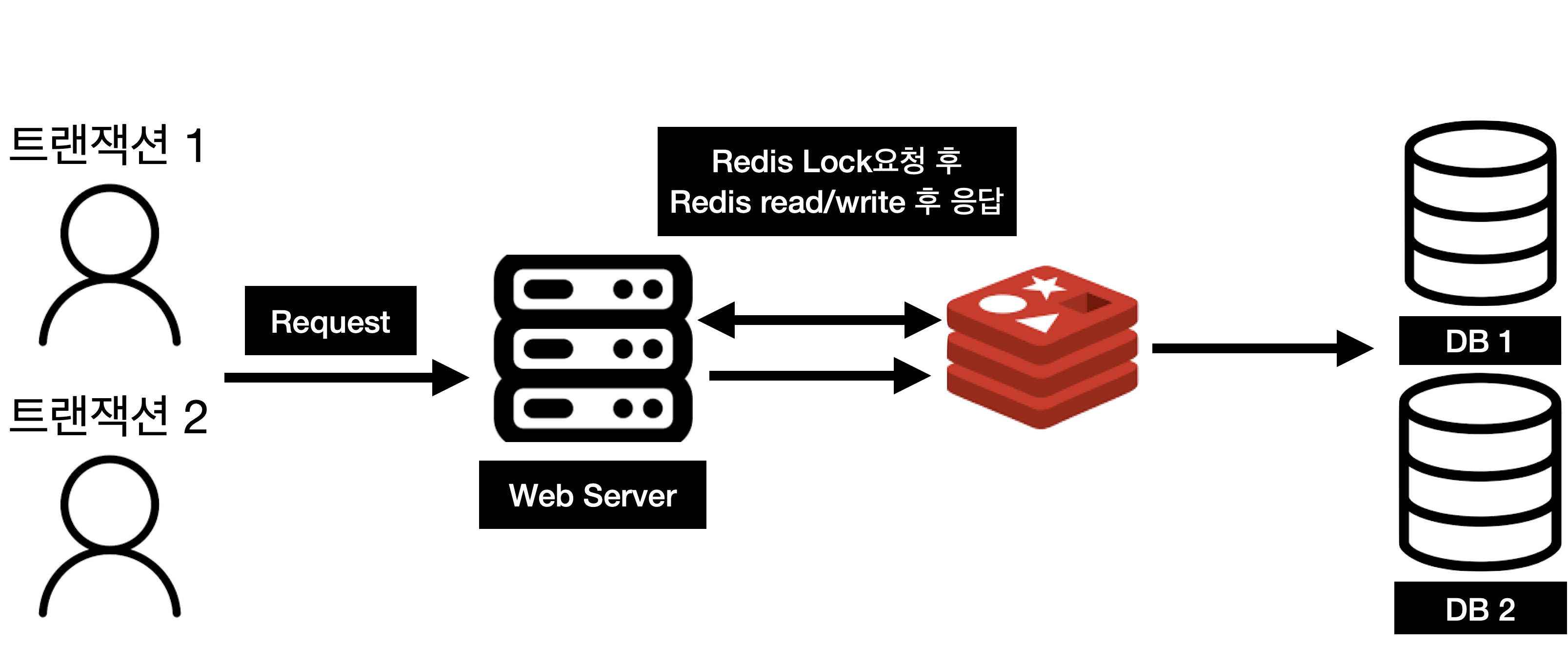
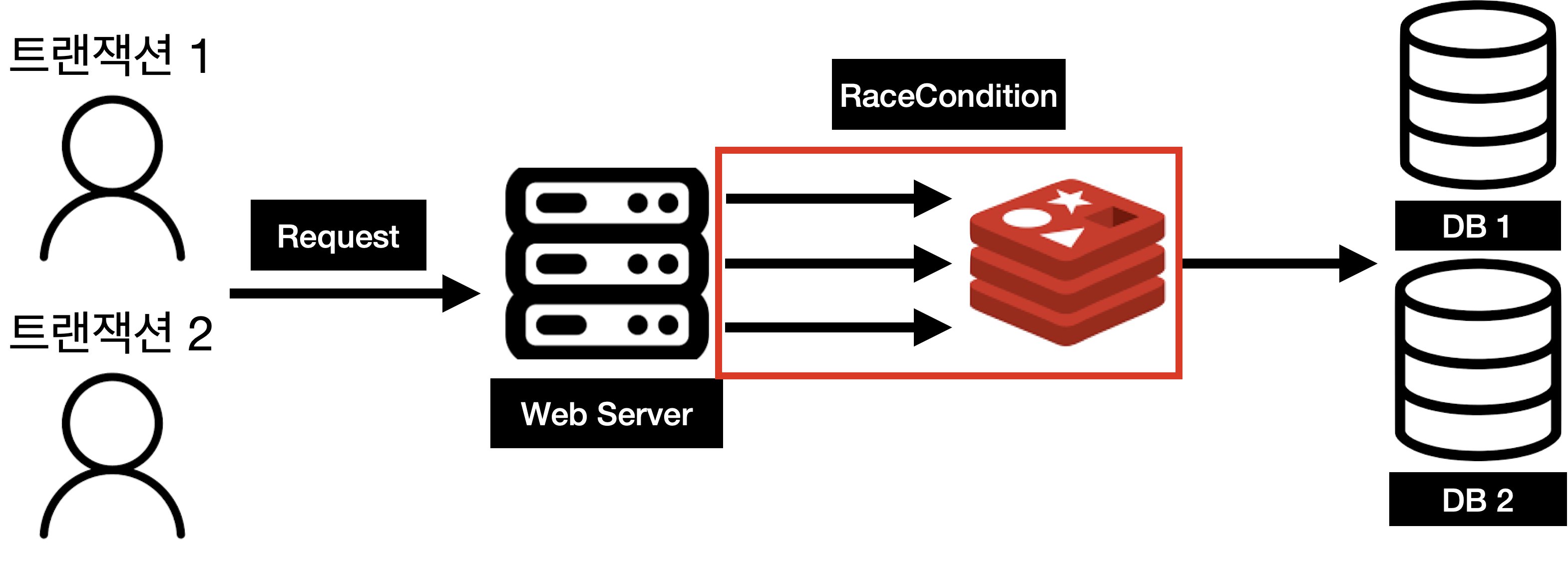
그럼 데이터베이스의 락은 필요가 없어지게 된다. Redis에서 경쟁조건을 해결하고 DB에 저장하기 때문이다.
왜 레디스인가
인메모리데이터베이스의 양대 산맥으로 memcached와 redis가 있다. 역시 대기업에서 표로 잘 표현해주셨다. 링크를 참조바란다. https://aws.amazon.com/ko/elasticache/redis-vs-memcached/
Redis vs. Memcached | AWS
Redis OSS와 Memcached는 인기 있는 오픈 소스 인 메모리 데이터 스토어입니다. 둘 다 사용하기 쉽고 고성능을 제공하지만 엔진을 선택할 때 고려해야 할 중요한 차이점이 있습니다. Memcached는 단순성
aws.amazon.com
성능 비교
두 데이터베이스의 성능을 비교해본 결과, 전반적인 성능은 비슷했다. 그러나 Redis에는 몇 가지 독특한 기능들이 있다. 그 중 하나가 Pub/Sub (게시/구독) 기능이다. 이 기능이 왜 중요한지 살펴보자.
서버 부하
Pub/Sub 기능을 사용하면 서버에 부하가 적게 걸린다. 이는 서버 간의 메시지 전송을 효율적으로 처리할 수 있도록 돕기 때문이다. 또한, Redis는 싱글 스레드로 동작하기 때문에 경쟁 조건 처리를 따로 하지 않아도 되는 장점이 있다. 이는 개발자가 동시성 문제를 신경 쓰지 않고도 안정적인 성능을 기대할 수 있다는 의미이다.
원자성 보장
Redis는 원자성을 보장해준다. 이는 여러 명령어를 하나의 트랜잭션으로 묶어서 처리할 수 있다는 것을 의미하며, 데이터의 일관성을 유지하는 데 도움이 된다.
이러한 이유들로 인해 Redis를 선택하게 되었다. Pub/Sub 기능, 싱글 스레드의 장점, 그리고 원자성 보장은 Redis를 Memcached보다 더 효율적이고 안정적인 선택으로 만든다.
경쟁조건
레디스를 도입하기 전에는 경쟁조건을 해결하기 비관적 Lock을 통해서 경쟁조건을 해결했다.(2024.07.23 - [TroubleShooting] - 발급 가능한 쿠폰의 개수보다 사용자에게 전달한 쿠폰의 개수가 더 많다....). 그렇다면 이젠 Lock 획득을 어디서 해야할지 생각해보면 정답은 레디스다.
왜 Lock을 Redis에서 걸어야 할까?
우리의 시스템 구조에선 사용자의 요청에 따른 처리를 하기 위해서 Redis를 참조한다. 따라서 경쟁조건이 발생하면 Redis에서 발생하지 DB에서 발생하지 않는다. 또한 Redis에서의 Lock 메커니즘은 DB에서의 Lock보다 훨씬 빠르게 동작한다.
그 이유는, DB에서의 Lock은 디스크 I/O와 연관되어 있어 성능 저하를 초래할 수 있지만, Redis에서는 모든 작업이 메모리에서 이루어지기 때문에 이러한 성능 저하가 발생하지 않는다.
Spring boot에서는 어떤 구현체를 선택해야할까?
이를 알기 위해서 기술블로그들을 참조했다. 궁극적으론 Redissession을 사용하기로 했는데 Lettuce 방식은스핀락 방식이여서 요청이 많을수록 레디스 서버에 부하를 주는 반면에 Redisssion은 Pub/Sub을 이용해서 Lock을 획득하기에 서버에 부하를 주지 않는다
결론
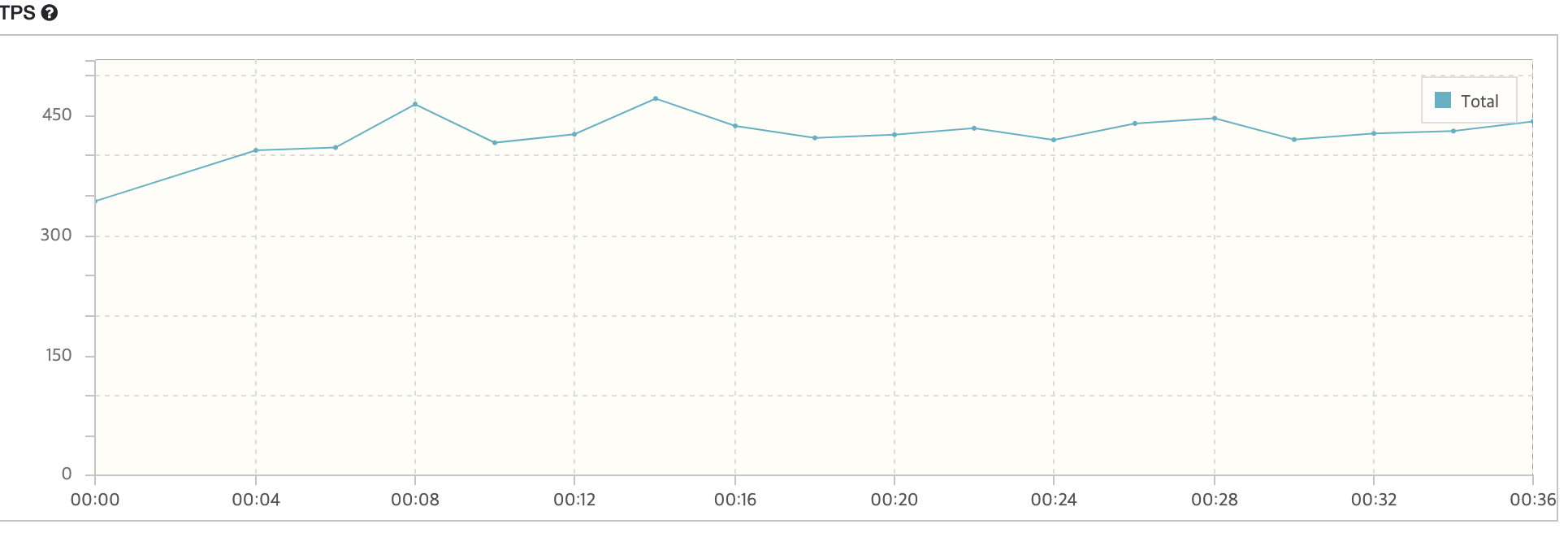
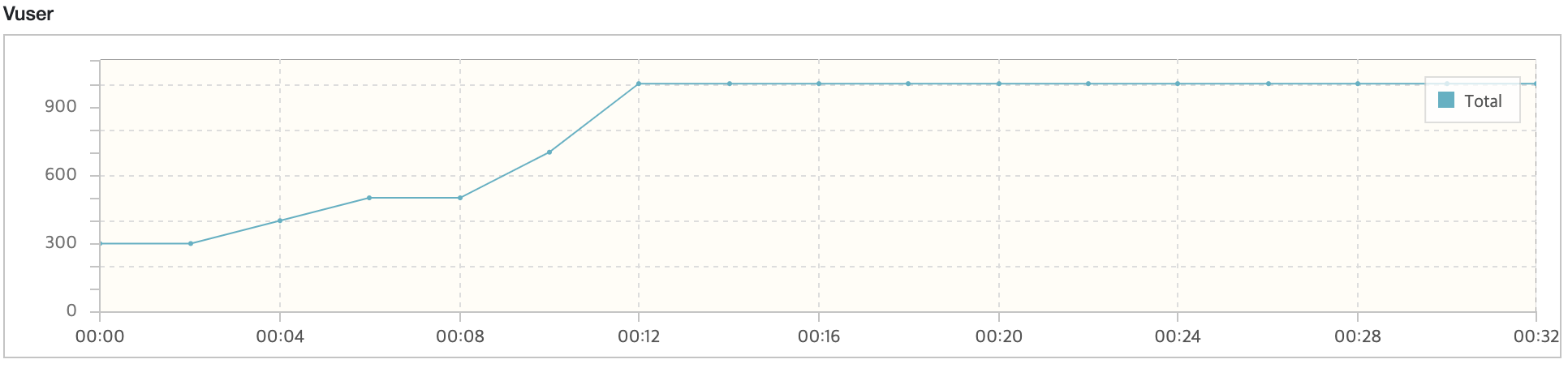
최종적으로는 user가 800명일 때, TPS는 450, 응답 시간은 1초로 성능을 개선할 수 있었습니다. MAX user은 800명까지 감당할 수 있는 것으로 확인했습니다. 그 이유는 800명부터는 TSP가 증가하지 않기 때문입니다. 아직 만족이 안되는 성능이지만 그래도 성능 개선의 포인트로 사용할 수 있다는 것을 알게 되었습니다.
[참고 자료]
마켓컬리 분산락
https://helloworld.kurly.com/blog/distributed-redisson-lock/
풀필먼트 입고 서비스팀에서 분산락을 사용하는 방법 - Spring Redisson
어노테이션 기반으로 분산락을 사용하는 방법에 대해 소개합니다.
helloworld.kurly.com
RDB와 Redis 성능 비교
'TroubleShooting' 카테고리의 다른 글
| 발급 가능한 쿠폰의 개수보다 사용자에게 전달한 쿠폰의 개수가 더 많다.... (0) | 2024.07.23 |
|---|---|
| 새로고침으로 발생하는 중복 데이터 전송 방지하기 (0) | 2024.05.05 |
| 파이썬 크롤링 작업 시간 단축하기 (0) | 2023.08.13 |
| telegram.error.NetworkErrorAsyncIO Event Loop Closed 오류 (0) | 2023.08.12 |
| Email attachment received as 'noname' 해결하기 (0) | 2023.05.09 |



